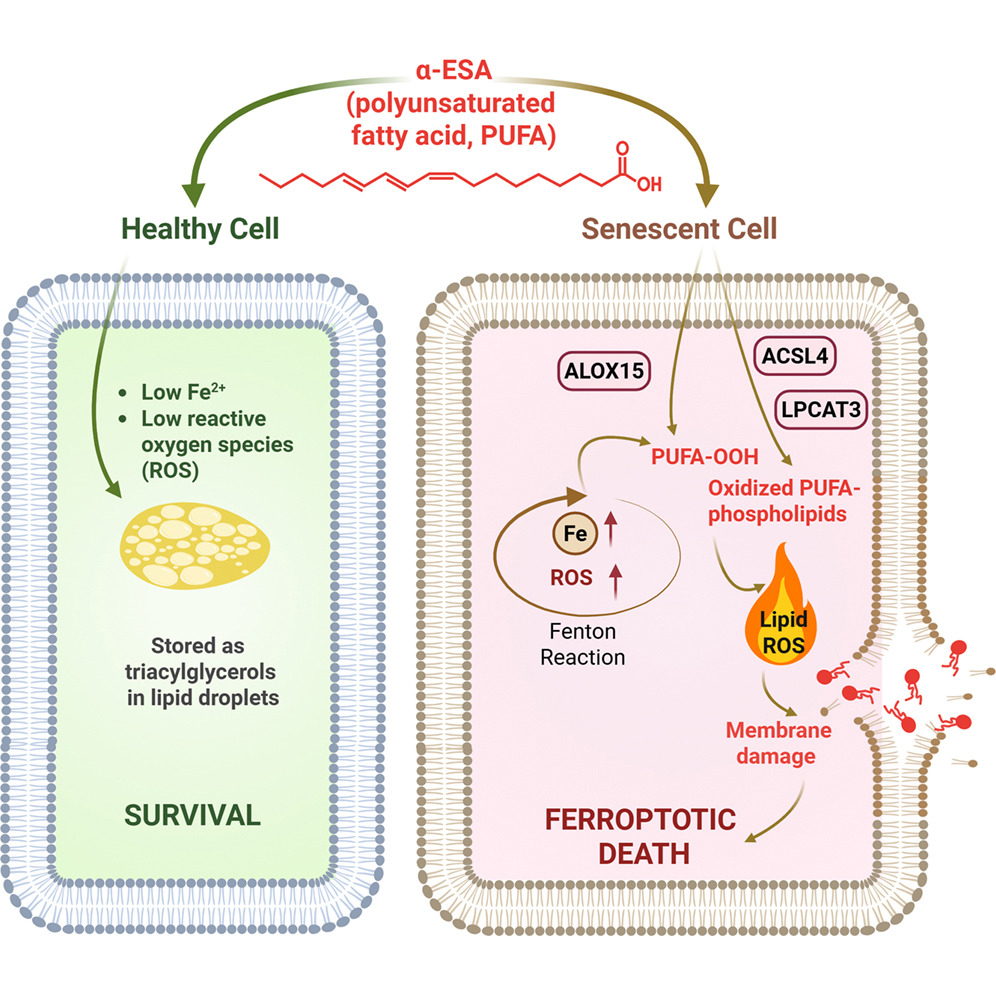
Cellular senescence, a state in which cells stop dividing but resist dying, accumulating in tissues over time, has emerged as one of the most promising targets in longevity medicine. Senescent cells actually serve important roles in development, wound healing, and cancer prevention, but as they accumulate with age or pathology, they become harmful: they secrete the senescence-associated secretory phenotype (SASP), a cocktail of pro-inflammatory factors, driving chronic inflammation, fibrosis, and tissue dysfunction, and “infecting” neighboring cells with senescence.
The seminal 2011 Baker et al. study showed that clearing senescent cells could extend healthspan in INK-ATTAC mice, giving rise to an entirely new therapeutic category. Since then, senolytics, which selectively kill senescent cells, and senomorphics, which modulate the SASP or reprogram senescent cells, have become major areas of research and investment.
The field is now transitioning from preclinical promise to clinical reality, with several companies advancing candidates into human trials across indications such as fibrosis, dermatology, and metabolic disease. However, significant challenges remain, including the lack of standardized biomarkers, the heterogeneity of senescent cell populations, and questions about safety and long-term efficacy. Some experts go as far as questioning the senescence paradigm itself. There have also been notable failures of senolytics in clinical trials, which has somewhat cooled down interest in the field.
We asked four leaders of senescence-focused biotech companies to discuss what drew them to the field, what makes their approaches unique, the obstacles they face on the path to the clinic, and what senotherapeutics might ultimately achieve for human health.
What do you find most compelling about senolytic/senomorphic therapies, and what convinced you that this path was worth pursuing seriously?
Marco Quarta, Co-Founder and CEO, Rubedo Life Sciences
What I find most compelling about senolytic and senomorphic therapies is their potential to address a root cause of aging. Cellular senescence is a causal driver of multiple chronic diseases, offering a rare medicinal opportunity to intervene upstream at a fundamental biological level rather than merely treating downstream symptoms.
My conviction grew from evidence showing how senescent cells actively orchestrate inflammation, fibrosis, and stem cell dysfunction. Recognizing that this biology is a major translational frontier led us to develop RLS-1496 at Rubedo. This first-in-class GPX4-modulating senotherapeutic emerged from ALEMBIC, our AI-driven multi-omics platform.
Seeing RLS-1496 progress into clinical trials across the U.S. and Europe has been the ultimate proof point. It transforms a fascinating scientific concept into a clinically actionable reality. For me, this confirms that the field is ready to move beyond discovery and into the lives of patients.
Lorna Harries, Professor of Molecular Genetics, University of Exeter; Founder, SENISCA
I first started thinking seriously about senescence as a drug target when the data emerged from the initial INK-ATTAC mouse studies. Until then, although there was evidence that these cells were deleterious, conclusive proof that they were drivers of aging rather than passengers was lacking. The work showing that removal of senescent cells improved functionality in multiple organ systems was very persuasive.
Going after the underpinning mechanisms of age-related disease rather than dealing with endpoint consequences is a much more efficient approach to medicine. At the moment, we patch up the consequences of ongoing disease after the event. Because the diseases of aging have common roots, many older people live with several chronic conditions and end up taking multiple drugs that can interact. Treatment is often delivered long after symptom onset, whereas an earlier, more proactive approach would allow us to reduce the drug burden on patients, simplify treatment regimens, and intervene earlier. The evidence base for senescence as a driver of disease is, in my opinion, now unequivocal. I think this is the new frontier of medicine.
Robin Mansukhani, CEO, Deciduous Therapeutics
Senescent cells are a compelling area for novel therapies because they are an upstream, multi-indication target. Senescent cells commonly express multiple fibrotic and inflammatory pathways, whereas most therapies target only a single pathway. These single-target pathways are often well downstream, providing only minimal and heterogeneous benefits. Our data supports senescence as a master regulator in both metabolic and fibrotic diseases.
Moreover, in the context of aging, most patients will have senescence-driven comorbidities. Systemically ablating senescent cells can have multi-indication impacts. Finally, with anti-senescence approaches, a single treatment often has durable effects lasting several months or more. Taken together, we believe an effective and safe anti-senescence approach could be revolutionary.
Adam Freund, Co-Founder and CEO, Arda Therapeutics
What I find most compelling isn’t the ‘senescence’ label, but the clinical power of targeted cell depletion. We’ve seen this work with B cells in autoimmunity, eosinophils in asthma, and myeloid cells in GvHD. If these relatively coarse strategies are effective, then a more targeted approach – the precise removal of only the most pathogenic cell states – likely represents a powerful therapeutic strategy that can be applied across multiple diseases and cell types.
Senescent cells have been postulated to drive multiple diseases, including aging itself, but this senescence hypothesis and its therapeutic corollary – targeting senescent cells for depletion (senolytic) or modulation (senomorphic) – has struggled to translate into patient benefit. This is because the senescence field is built on a paradox: it is simultaneously too narrow in its foundational models and too inclusive in its subsequent definitions.
First, the field anchors on a narrow set of in vitro models that don’t reflect human disease (e.g., DNA damage-induced senescence in fibroblasts) to define senescence markers (e.g., p16, Bcl-2, SA-β-gal, or inflammatory cytokines). Then it shoehorns any in vivo cell expressing a handful of those markers into the senescence bucket.
This creates a spurious framework in which vastly different cell states are deemed biologically related and assumed to play similarly causal roles in disease. In reality, single-cell data show that traditional in vitro models of senescence have little overlap with cell states found in human disease, and the classic markers of senescence are expressed by a multitude of normal cell types and cell states.
The senolytic field has provided preclinical proof of concept that we can safely apply cell-depleting strategies to solid tissues and non-immune cells. This is a significant technical advance. However, the next era of clinical success will come from moving away from this in vitro-defined cell state and instead mapping the unique endogenous cellular architecture of each human disease to identify and surgically eliminate the specific aberrant cell states driving it forward.
How is your company unique in the senescence landscape – what is your technical approach, and why was it chosen?
Marco Quarta
Rubedo is unique because we rejected the idea of senescence as a monolith. Senescent cells are heterogeneous and context-dependent; they are only meaningfully druggable if you understand their specific vulnerabilities. Our philosophy is precision senotherapeutics: identifying functional dependencies and designing selective therapies matched to specific disease biology.
Our technical edge lies in ALEMBIC, which resolves cell heterogeneity at high resolution. This platform allowed us to identify GPX4-related biology as a critical vulnerability in certain senescent states. By focusing on how these stress-adapted cells survive, we can disrupt them with surgical precision.
This is no longer just a discovery story. With RLS-1496 in the clinic, we are validating a novel mechanistic approach. We aim to move the field away from “broad-spectrum” hits toward therapies that are selective, practical, and biologically grounded.
Lorna Harries
I think our work is quite different from other players in the space. There is some amazing work going on in senomorphics, in senescent cell subtype-specific senolytic approaches, in immune rejuvenation, and in epigenetic reprogramming. Our approach is a bit different. We were among the first academic teams to demonstrate that senescence was not irreversible and have been researching the underpinning biology of the systems we are targeting in an academic setting for decades. This has allowed us to identify a novel and unique point of traction that works with the cells’ own biology.
We have a unique single-gene reprogramming approach, distinct from conventional epigenetic reprogramming, that works with the underpinning biology of the genes in question to restore their natural, endogenously regulated gene expression. It’s not an overexpression or a knockdown of genes involved in senescence; it’s a resetting of the cell’s ability to properly regulate them. I wish we could say we chose it, but it’s just what our technology does! We think it will be useful for preservation of cellular function in the correct cellular context, leaving the cells where they are with all the cell-to-cell crosstalk maintained and the correct tissue microenvironment intact.
Robin Mansukhani
It is well understood that an effective immune system can quickly recognize and ablate senescent cells. However, this immune function – specifically that of iNKT cells – becomes compromised over time. First, we did the heavy lifting to understand which immune cells (Natural Killer T cells) were actually responsible for senescence removal. Subsequently, we designed a novel small molecule that specifically restores NKT function, leading to single-dose disease efficacy in metabolic and fibrotic diseases.
Off-target safety issues have been a primary bottleneck in the senescence field. This is because many senolytic therapies are repurposed cancer therapies. As a result, they often target not just senescent cells but also healthy cells for removal based on non-specific anti-apoptotic pathways. Our approach is to restore endogenous immune pathways. Additionally, we have not observed any safety issues even at 30x the efficacious dose.
Adam Freund
Most companies in the senescence space are built on a “senescence-first” hypothesis: starting with senescent cell markers and then searching for diseases where those markers are expressed. However, as discussed above, single-cell data demonstrate that the classic in vitro senescence phenotype does not occur in most diseased human tissues, and indexing on markers identified in artificial models has led to repeated translational failures across the industry.
Arda’s approach is fundamentally “disease-first.” Rather than searching for senescent cells, Arda’s platform identifies and targets disease-driving cell states, irrespective of their relationship to traditional senescence markers.
We leverage a high-resolution discovery engine to pinpoint the specific cell populations most clearly linked to causal involvement in disease. By combining large-scale, multi-modal single-cell transcriptomics with human genetics and disease biomarkers, we identify pathogenic cell states at a granular level. Once a pathogenic state is identified, we integrate transcriptomic and proteomic data to nominate high-fidelity surface markers, enabling the design of therapies that offer selective and sensitive depletion of target cells while sparing healthy tissue.
This cell-centric approach yields more tractable and durable interventions. Instead of attempting to tune individual pathways or unravel complex and redundant intracellular signaling, we eliminate the dysregulated cells themselves. This “reset” of the tissue microenvironment bypasses the limitations of molecular modulation via a mechanism of action that removes the source of the pathology.
What is your strategy for bringing your therapy to the clinic, including target indications and work with partners and regulators?
Marco Quarta
Our strategy focuses on indications where senescence is measurable and clearly pathogenic, such as dermatology and fibrotic disease. For RLS-1496, we utilized a unique design, skipping healthy volunteers to test the drug directly on various patient groups in a “basket trial.” By testing both chronic skin lesions and healthy skin, we are simultaneously evaluating effects on disease and skin aging.
This approach treats the skin as a “fast track” validation gateway for future systemic expansion. We also prioritize regulatory alignment and early engagement with the FDA and EMA. One of the major bottlenecks is the lack of standardized biomarkers, which is why I am involved with the Phaedon Institute to build a shared translational framework.
Partnerships are central to this. We work with academic and industry leaders to ensure our data is robust. If the field is to succeed, we need not only strong drugs but also a clear, unified path for how senescence is measured and interpreted in humans.
Lorna Harries
Like other approaches that target senescence, our technology has the potential to impact multiple age-related diseases and beyond. Our early market research indicated opportunities in several applications, including medicine and cosmeceuticals, and we have exploited both. We are developing oligonucleotide therapeutics for aging diseases, initially idiopathic pulmonary fibrosis (IPF), because it’s a bona fide senescence disorder, designated as a rare disease (and thus eligible for orphan drug designation), and there is a real clinical need. We see this very much as a gateway indication, though: proof of concept in this area will open the doors to other diseases.
The barrier for wider expansion is not “does the drug work” but “can we deliver it.” Oligonucleotides have several important advantages over a conventional small-molecule approach in that you can drug the undruggable in a precise and targeted manner. Off-target profiles and drug tolerability are often much cleaner than with small molecules. The challenge is getting them where they need to be. We have tried our lead asset in multiple different cell lineages and know it works in cells from the skin, lung, brain, joint, and eye. We made an early strategic decision to focus on diseases where local delivery was possible for an earlier clinical win. In the longer term, as the technology evolves, we fully intend to move into diseases that require more complex delivery.
In the medical aesthetics space, we have been very successfully partnered with a global leader in the cosmeceutical space to deliver new skin health options, which has validated our technology and will provide human in vivo proof of concept.
Robin Mansukhani
We focus on senescence-driven indications such as lung fibrosis and various metabolic diseases. As these are comorbidities, we plan to collect multiple disease readouts in our first clinical studies. Our goal is not just to produce an effective therapy for removing senescent cells but, more importantly, to demonstrate a significant improvement over the current standard of care in the specific disease indication. In the future, we also plan to test age-related cancers, autoimmune disorders, and genetic disorders.
Adam Freund
We are pursuing precision cell depletion across multiple inflammatory and immunological indications, with an initial focus on fibrosis. Each program is optimized for its specific disease context, including target selection, molecule design, and clinical and regulatory strategy.
How close do you think we are to seeing multiple approved senolytic/senomorphic therapies, and what most limits the pace of progress today?
Marco Quarta
We are significantly closer to approved therapies than we were even three years ago. The shift from “conceptual excitement” to “mechanical execution” is evident as novel senolytic mechanisms like GPX4 modulation and novel senomorphic mechanisms like PAI-1 inhibitors have entered the clinic and are advancing to Phase 2 studies. However, the pace is still limited by translational complexity: senescence manifests differently across tissues and disease stages.
The two biggest hurdles are biomarkers and funding. We lack standardized ways to confirm target engagement and link biological changes to clinical outcomes. Additionally, while the field has matured, it requires sustained financial support to overcome the hurdles typical of any emerging therapeutic class.
The science is robust, and the opportunity is real. The field will advance fastest if we combine innovative biology with rigorous clinical trial design and a focus on validated measurement tools.
Lorna Harries
I think we are still some way off, but we are seeing more and more early entries into the clinic now. One thing that has hindered wider adoption of these emerging technologies is that we still lack standardized and validated biomarkers to link reduction or reprogramming of senescent cells to disease outcomes in trials. The clinical arena has very well-defined outcomes for most of the disorders we are aiming to treat, but the challenge is how we link those outcomes to traction on senescence.
Drug regulatory frameworks may also require adjustments to fold these new approaches into the mainstream. It’s easy to forget that this is a very new field that requires a regulatory and policy mind shift, so we should not be surprised that existing infrastructure is not yet set up to assess and evaluate these therapies. Our approaches remain very different from the established one-drug-one-indication model that has been the status quo until now and is familiar to regulatory authorities and big pharma partners.
Once we see real traction in the clinic from one of these early adopters, I think the floodgates will open. A win for one of us is a win for the field and will create opportunities for others. These are still early days, though, and we need to move carefully and with consideration.
Robin Mansukhani
The primary bottleneck is safety. Most senolytic therapies are repurposed cancer drugs and have off-target effects, resulting in a very narrow therapeutic window. While this may be acceptable in oncology settings, it is a bottleneck in chronic age-related diseases. That said, there are a few next-generation senolytic therapies in the clinic or approaching clinical studies now. These approaches have demonstrated cleaner safety profiles and therefore larger therapeutic windows. As such, we believe early proof of concept in senolytics is no longer far off.
Adam Freund
I believe we are far from seeing a wave of approvals, if that milestone is ever reached. The field is bottlenecked by a “senescence-first” framework that starts with a hammer and searches for a clinical nail rather than seeking a ground-up understanding of disease biology.
This problem is exacerbated by the field being trapped in a circular technical loop. First, it relies on cell culture models that bear minimal resemblance to the cell states driving human disease. Then it uses an overly flexible definition to bridge the translational gap: the few markers defined from those artificial models are used to identify cells in disease. When those markers are found, it “validates” the original in vitro model, ignoring the fact that the rest of the cell’s phenotype is entirely different.
This loop persists because a rigorous, full-phenotypic comparison between the model and the human disease state is rarely performed, leaving the field to chase reductionist signatures that increasingly appear irrelevant to most human pathology. Until we stop trying to validate a pre-defined category and start identifying causal, disease-specific cell populations, translational failures will likely continue.
What do you expect senolytic/senomorphic therapies will be able to do for humans in the short and long term?
Marco Quarta
In the short term, I expect senotherapeutics to show immense value in specific diseases where senescence is clearly pathogenic, such as fibrosis, chronic inflammatory conditions, and metabolic disorders. These therpies will reduce pathological inflammation and restore regenerative capacity with long-term, sustained effects in ways that conventional medicines cannot.
Looking ahead, we are envisioning a preventive medical paradigm. By restoring tissues to a physiological state before overt disease emerges – similar to how we approach prediabetes – we can delay or attenuate multiple age-related conditions by treating preconditions predicted by cellular senescence-related biomarkers.
Senotherapeutics won’t “solve” aging alone; it is a multifactorial process. However, they will be a foundational pillar of longevity medicine alongside metabolic and epigenetic interventions. The goal is to preserve function and resilience for as long as possible, fundamentally changing the human experience of growing older.
Lorna Harries
I think these approaches have truly transformational potential. In the short term, we will be able to provide better options for the treatment of specific age-related diseases that differ from what’s currently available because they will be genuinely disease-modifying.
I also think it’s possible that early treatment for one aging disease will delay the onset of others, so we may see knock-on benefits for organ systems outside the original site of treatment. If we are successful, we may find ourselves in a situation where only a couple of drugs are needed to treat multiple diseases, which would reduce healthcare costs and improve quality of life.
In the longer term, I think prevention of disease will become an option. We will be able to treat earlier, with simplified drug regimens, that will give better outcomes for patients. It may be that at the time of diagnosis of their initial chronic age-related disease, patients could be offered preventive, proactive medicines to delay or even prevent the next one. With preventive treatment, the risk-benefit relationship is obviously different, so thorough assessment of long-term safety will be necessary, but I think this is an enormously exciting area.
Robin Mansukhani
I believe anti senescence therapies with strong safety and efficacy profiles will serve as single agent therapies with multi-indication impacts. Given most anti-senescence therapies are small molecules, the cost and patient access are quite attractive. Consequently, I believe the right therapy will be revolutionary and widely adopted by the broader global population.
Adam Freund
I think the term “senolytic” will eventually fade from the clinical lexicon, as it does not provide a unifying framework that simplifies the search for targets or increases the chance of translational success. If senescence, by some permissive definition, actually plays a role in multiple diseases, it is a sufficiently heterogeneous process that any therapies eventually approved will be as distinct in their mechanisms and target populations as any two unrelated medicines. Consequently, “senolytics” is unlikely to become a meaningful therapeutic category.
In the long term, success in the pathogenic cell space will not look like a single drug that removes senescent cells to treat multiple diseases; it will be a suite of highly specific, cell-centric therapies designed to deplete the exact pathogenic populations driving individual diseases.
We would like to ask you a small favor. We are a non-profit foundation, and unlike some other organizations, we have no shareholders and no products to sell you. All our news and educational content is free for everyone to read, but it does mean that we rely on the help of people like you. Every contribution, no matter if it’s big or small, supports independent journalism and sustains our future.